Usually, if I write a script, I do not prefer to store any parameter or input value as hard coded onto the scripts. And those long parameter lists seems clunky for me. Due to this reason, I made a simple key-value data storage for my local running scripts.
Repositories and packages
Repository of the main project: Global variable service provider. In the project I used one of my packages, its repository can be found here: Simple in memory .NET database repository and MemoryDbLibrary Nuget package. I will highlight some details about it, but the whole code can be located on these pages.
Overview
As I mentioned I am not prefer to store my inputs and filters separately from my program/script logic. It may make it more complicated a bit, but it has an advantage: if I had to modify a monitor routine (e.g.: new file system I need monitor) then I need only change the data part and not code. Thus I do not need to re-test the code because that is unchanged.
I could use existing database solutions but they would be over complicated for this situation. Even a Redis database too. I do not need to access this data from another computer, I just need it locally. I also do not user authentication and authorization. So instead using which is overkill, I made a pure and small database, this is the MemoryDbLibrary package. This is the hearth of this application.
Simple in memory database
As it is a simple package it does not have too much abilities, only what is needed for me. These actions are the following:
- Add/Change/Remove record
- List all records
- List sub records
- Save records into file as persistent storage
- Load records from file
The key can be added like a file path. For example, the following key-value pairs are valid pairs:
settings/port-master 10245 settings/port-slave 10246 settings/port-agent 10247 settings/target-list host1.com host2.com host3.com settings/log-path /var/log/app.log monitor/memory on monitor/memory/limit 8000 monitor/docker on monitor/docker/list gitlab pgadmin postgres monitor/docker/gitlab-status ok monitor/docker/pgadmin-status ok monitor/docker/postgres-status ok
From outside of the database engine, it can be seen only key-value tuples and dictionaries. Inside the engin, it is not one consistent list. It is like a hash-table chain for searching values faster. Due to this fact, this database is suitable if the read requests are rather executed then update/create requests. The list, above, is stored in the memory with the following representation:
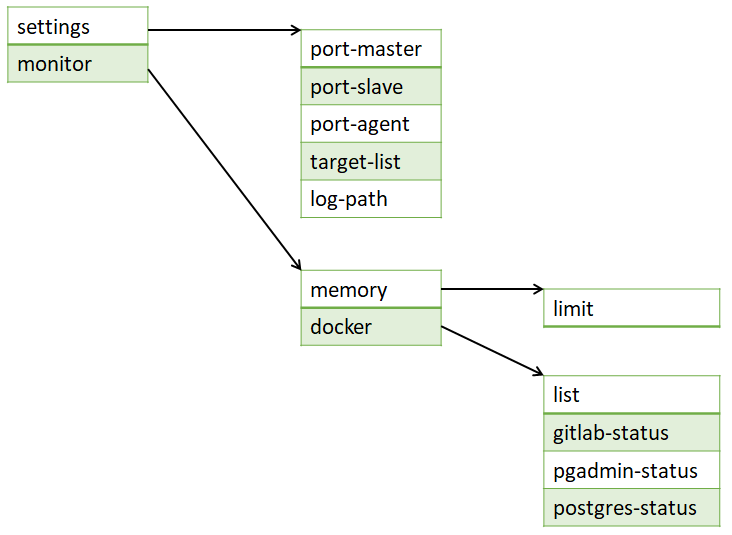
As you can see every list element has a key, a value and sub-list, which point towards “sub directories”. I used this design because I plan to use it my other projects and its template will be useful there (technically this application is just a bi-product of that).
For more details about the methods, please check the README.md file in github repo.
Global variable service provider
From the application view the following sequence is happening:
- Initialization of ThreadPool
- Initialization of MemoryDB from MemoryDbLibrary Nuget package (explained above). Persistent file storage is the first parameter if program
- Create a receiver named pipe based on second parameter of program
- Wait until request is received
- Pass the task to one of the background process and jump the previous point
- The background task is executing the requested action and send the output back
From the user view, the following must happen:
- Create a name pipe with
globvar-<pid>naming convention - Send request to the application in the following format:
<pipe-path> <action> - Wait for
globvar-<pid>file write - Read the file, output from application is there
The following shell script can be used to make it simpler:
#!/usr/bin/sh
pipe_dir=/tmp
mkfifo ${pipe_dir}/globvar-$$ -m666
echo -n "${pipe_dir}/globvar-$$ $*" > ${pipe_dir}/globvar-in
respond=$(cat ${pipe_dir}/globvar-$$)
rm ${pipe_dir}globvar-$$
echo "${respond}"
exit 0
Process flow can be seen on the following figure, but for more details and information about the installation please check the README.md file in github repo.

Example usage of this function
I will cut some details from my monitoring shell scripts. They are mostly triggered by cron but some runs after boot. First example is running after system is booted. It is checking that every file system is mounted correctly during boot. As you can see it simply using globvar getdir command to get every monitor/fs/points related record. Then it check /proc/mounts file. If it found any missing, it created an incident for me by using HomeTicketCtl command.
If I would need to add new file systems or change them in the future, I can simply can by globvar set command and make them persistent as they are parameters by globvar save command.
#!/usr/bin/bash
# --- Read the monitored points ---
mounts=()
i=0
while IFS=$'\n' read -r line
do
found=$(cat /proc/mounts | awk '{print $2}' | grep "${line}")
if [[ -z ${found} ]]
then
HomeTicketCtl -a CreateTicket -s File system is missing: ${line} -r fs_check_${line} -c System -t Missing file system
fi
done < <(globvar getdir monitor/fs/points | awk NF | awk '{print $2}')
Another example can be my gitlab monitor. It check my Gitlab status in every 10 minutes by cron but ticket would be opened only, if 2 failure happened in row.
#!/usr/bin/bash
# --- Get the current status ---
readiness1=$(curl --insecure https://gitlab.atihome.local/-/readiness 2>/dev/null | jq '.master_check[] | .status')
readiness2=$(curl --insecure https://gitlab.atihome.local/-/readiness 2>/dev/null | jq '.status')
liveness=$(curl --insecure https://gitlab.atihome.local/-/liveness 2>/dev/null | jq '.status')
# --- Get the previous ---
old_readiness1=$(globvar get monitor/gitlab/readiness1 | awk '{print $2}')
old_readiness2=$(globvar get monitor/gitlab/readiness2 | awk '{print $2}')
old_liveness=$(globvar get monitor/gitlab/liveness | awk '{print $2}')
# --- Open ticket only when the previous check was also not ok ---
if [[ ${readiness1} != '"ok"' ]] && [[ ${old_readiness1} != '"ok"' ]]
then
HomeTicketCtl -a CreateTicket -s Healtcheck failes: readiness1 -t Gitlab monitoring issue -c Application -r gitlab_readiness1
fi
globvar set monitor/gitlab/readiness1 ${readiness1}
if [[ ${readiness2} != '"ok"' ]] && [[ ${old_readiness2} != '"ok"' ]]
then
HomeTicketCtl -a CreateTicket -s Healtcheck failes: readiness2 -t Gitlab monitoring issue -c Application -r gitlab_readiness2
fi
globvar set monitor/gitlab/readiness2 ${readiness2}
if [[ ${liveness} != '"ok"' ]] && [[ ${liveness1} != '"ok"' ]]
then
HomeTicketCtl -a CreateTicket -s Healtcheck failes: liveness -t Gitlab monitoring issue -c Application -r gitlab_liveness
fi
globvar set monitor/gitlab/liveness ${liveness}
Final words
I explained that I prefer the parameters and settings store outside of my scripts and programs. I also mentioned that for my local monitor scripts a normal database, even a Redis, would be overkill. Thus I made a light database for this and I showed a practical example for its usage.

