During to coming hobby projects I plan to use database to store text types with different lengths. I made an investigation and run some test to try what and how PostgreSQL store and work with text types. This article is result of this process.
What and why did I test?
I have tested the performance with text type fields (varchar and text). I also run some test about TOAST to see and understand how PostgreSQL store the bigger texts (like pages or documents). Test was running in this environment:
- Debian 10.10
- PostgreSQL 13.4
- About hardware, it is a Ryzen 3200G with 16GB DDR 2133Mhz RAM. Database is running for a SATA SSD (Crucial MX 500)
I did the test mainly because I was curious and I wanted to learn some own conclusion about how I should design my tables during upcoming home projects. Test has 3 main parts:
- Varying character VS text types
- Effect of TOAST
- TOAST vs no TOAST
Text vs varchar – Test and conclusion
Due to PostgreSQL documentation there is no difference among them from performance view. There is a third type, called character(n) which is a fix length (filled up with blank) a which has some additional CPU cycle (due to fill up space), so I analyzed only text and varchar types.
There is no performance difference among these three types, apart from increased storage space when using the blank-padded type, and a few extra CPU cycles to check the length when storing into a length-constrained column. While
PostgreSQL: Documentation: 13: 8.3. Character Typescharacter(has performance advantages in some other database systems, there is no such advantage in PostgreSQL; in factn)character(is usually the slowest of the three because of its additional storage costs. In most situationsn)textorcharacter varyingshould be used instead.
I have created 2 tables: each has 2 columns: id and content. Difference that text_char has varchar(256) and text_text has text type on content column. At the end, database size was exactly same. I have performed the following tests multiple time, and checked the result’s average on both table:
- Insert half million records:
WITH str AS (SELECT random_string(256) as value) INSERT INTO xxxxxxxx (content) SELECT value FROM generate_series(1, 500000), str; - Query all records:
SELECT * FROM xxxxxxxx; - Query with text filer:
SELECT * FROM xxxx WHERE content LIKE '%something%'; - Delete half million records:
DELETE FROM xxxxx WHERE ID IN (SELECT id FROM xxxxx LIMIT 500000) - Update specific record:
UPDATE xxxxx SET content = random_string(256) WHERE id = 3568;
Result has no any unexpected result, it is same on different types.
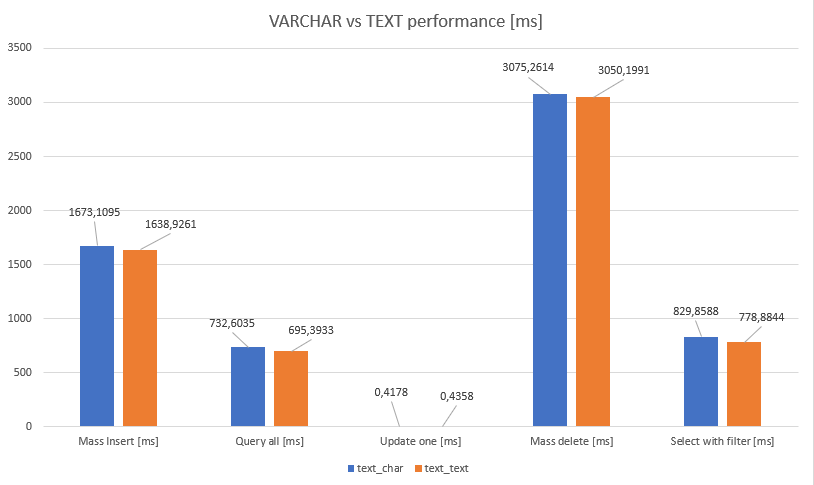
The results shows exactly same thing what is documented. There is no performance difference among the types. But I will go with text type in the future because it is simpler to use. If I will ever need length limitation, I would use constraint. It simply seems easier manageable and it has no performance impact like in other database software.
What about to store longer texts?
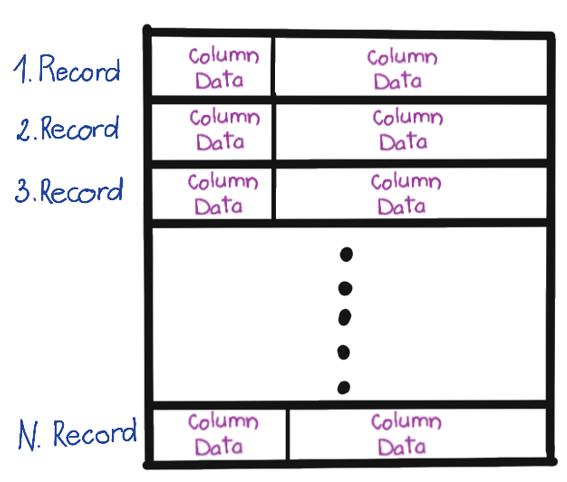
Before introduce this feature, let’s see how records are stored on inline mode. During inline mode, each byte is in the table, nothing is external. Following hand-made figure represent that each column data is “in the line”, so they are in the table:
But there are no infinity space in the line. For longer texts, PostgreSQL has a feature called TOAST (The Oversized-Attribute Storage Technique).
PostgreSQL uses a fixed page size (commonly 8 kB), and does not allow tuples to span multiple pages. Therefore, it is not possible to store very large field values directly. To overcome this limitation, large field values are compressed and/or broken up into multiple physical rows.
PostgreSQL: Documentation: 13: 69.2. TOAST
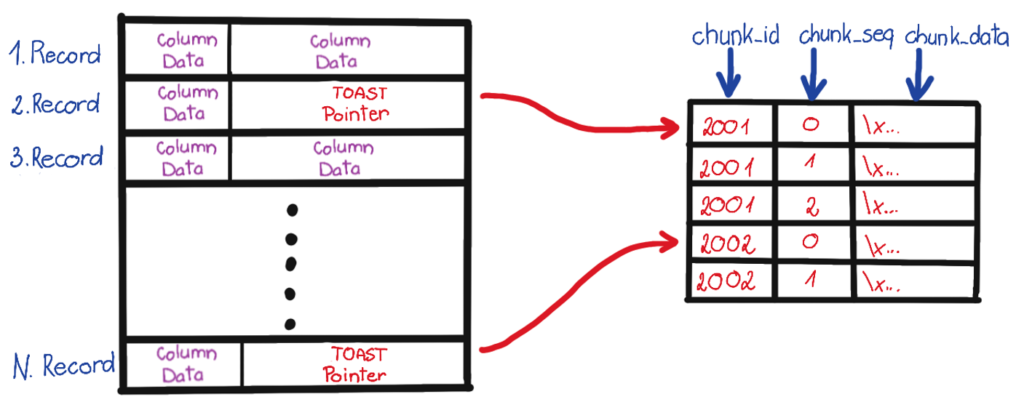
So with other words, if we would like to store longer texts (for example pages, posts or codes), database breaks it for more chunks and store them separately. Good news, that we do not need to take care with this because database doing it under the hood. Each table has a TOAST table, which has 3 columns:
chunk_id: one record can have more chunk. These chunks are grouped by this idchunk_seq: sequence number of chunkchunk_data: data of the chunk
Not each type has TOAST feature, but for example text type has. The TOAST management code recognizes four different strategies for storing TOAST-able columns on disk:
PLAINprevents either compression or out-of-line storage; furthermore it disables use of single-byte headers for varlena types. This is the only possible strategy for columns of non-TOAST-able data types.
EXTENDEDallows both compression and out-of-line storage. This is the default for most TOAST-able data types. Compression will be attempted first, then out-of-line storage if the row is still too big.
EXTERNALallows out-of-line storage but not compression. Use ofEXTERNALwill make substring operations on widetextandbyteacolumns faster (at the penalty of increased storage space) because these operations are optimized to fetch only the required parts of the out-of-line value when it is not compressed.PostgreSQL: Documentation: 13: 69.2. TOAST
MAINallows compression but not out-of-line storage. (Actually, out-of-line storage will still be performed for such columns, but only as a last resort when there is no other way to make the row small enough to fit on a page.)
During tests, I used the EXTENDED type, which is the default for text type. Not each record has TOAST records.
The TOAST management code is triggered only when a row value to be stored in a table is wider than
PostgreSQL: Documentation: 13: 69.2. TOASTTOAST_TUPLE_THRESHOLDbytes (normally 2 kB). The TOAST code will compress and/or move field values out-of-line until the row value is shorter thanTOAST_TUPLE_TARGETbytes (also normally 2 kB, adjustable) or no more gains can be had. During an UPDATE operation, values of unchanged fields are normally preserved as-is; so an UPDATE of a row with out-of-line values incurs no TOAST costs if none of the out-of-line values change.
We can change TOAST_TUPLE_TARGET value by parameter per table using ALTER TABLE xxxx SET (toast_tuple_target = xxx) where xxx must be minimum 128.
Method of TOAST is represented on the following hand-made figure.
Find the TOAST table
By 2 query (or a complicated one), TOAST table name can be gathered. You must replace the “toast_huge” with your table name.
postgres=# SELECT reltoastrelid FROM pg_class where relname = 'toast_huge';
reltoastrelid
---------------
128491
(1 row)
postgres=# SELECT relname FROM pg_class WHERE oid = 128491;
relname
-----------------
pg_toast_128487
(1 row)
postgres=# SELECT count(*) FROM pg_toast.pg_toast_128487;
count
--------
250000
(1 row)
TOAST – Test and conclusion
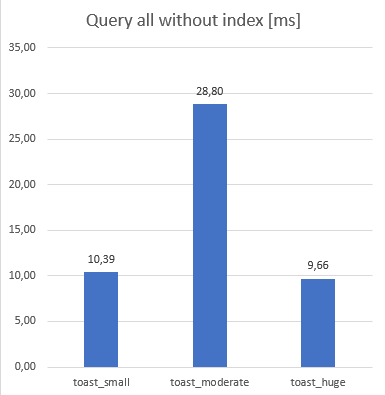
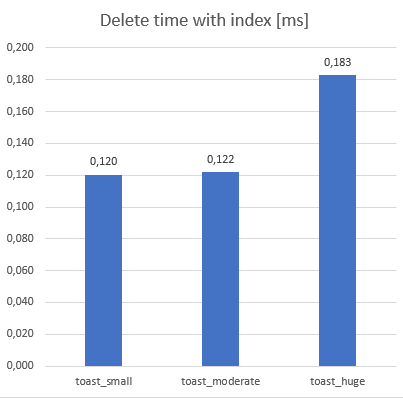
I made 3 tables. Each table has an id serial and content text columns. Each table had 50000 records.
toast_small: it stores small data, only 32 character long records. It is stored inline.toast_moderate: it stores 1850 character records (near theTOAST_TUPLE_THRESHOLDlimit). It is bigger, but still stored inlinetoast_huge: it stores 8100 character long records. They are stored out of line.
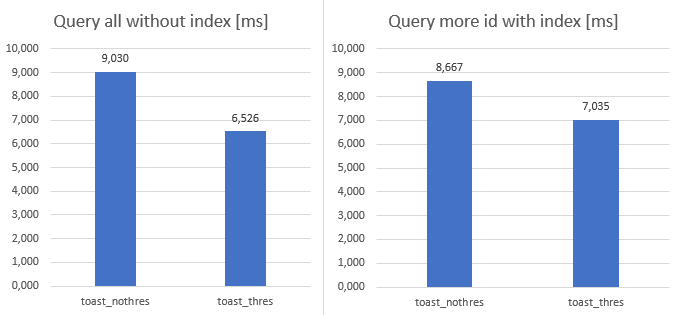
During the first test, it can be seen the advantage of that data is out of line. Due to this, during SELECT * FROM xxxxx query was faster for the huge table than moderate significantly, even it had ~4 times bigger data! Which is surprising that it has same response time, then the smallest table has! It was ~3 times faster than moderate!
Advantage of out of line strategy also could be seen, when SELECT * FROM xxxx WHERE id > 7000 AND id < 25000 test was executed. Similar result can be seen then the during previous test:
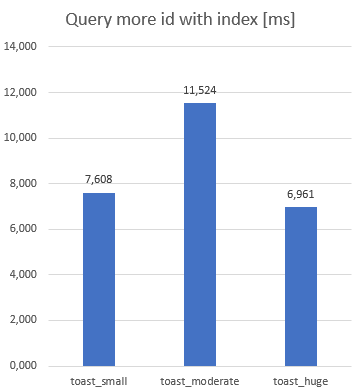
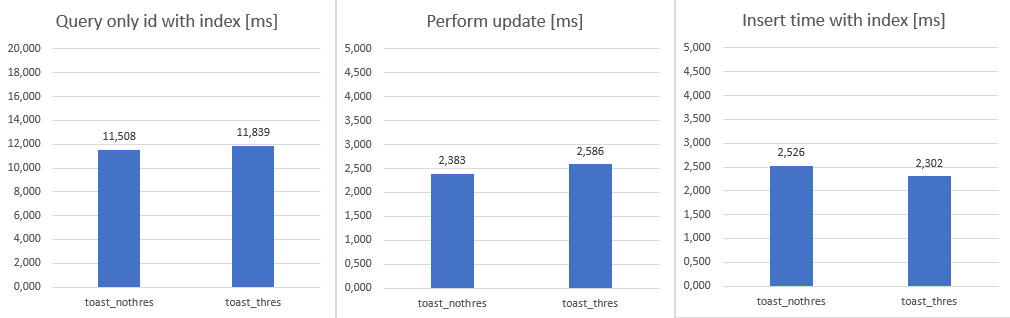
But as the content filed was out of scope (SELECT id FROM xxxx) all table performed same:
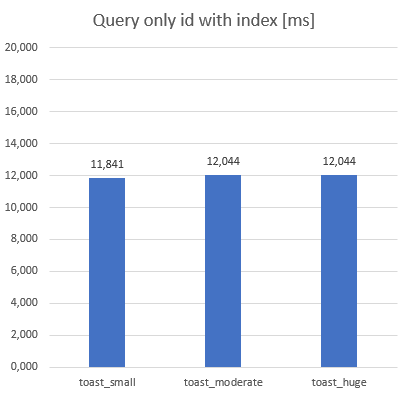
Difference also disappeared when we used index for a single query (SELECT * FROM xxxx WHERE id = 33):
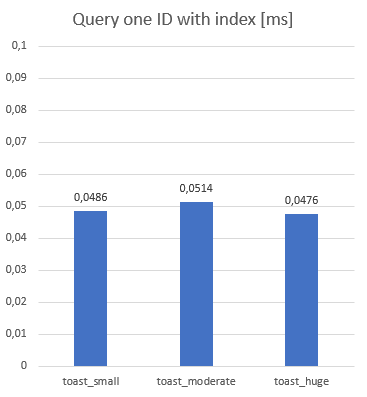
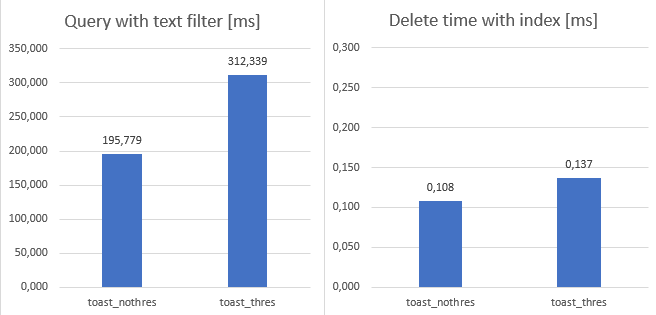
Some test result was as I expected. When we were filtering in text (SELECT * FROM xxxx WHERE content LIKE '%something') query or performing update (UPDATE xxxx SET content = random_string(n) WHERE id = 3200) or make an single insert (INSERT INTO xxxxx (content) VALUES (random_string(n))) result was expected. Because bigger tables works with bigger data, it takes more time
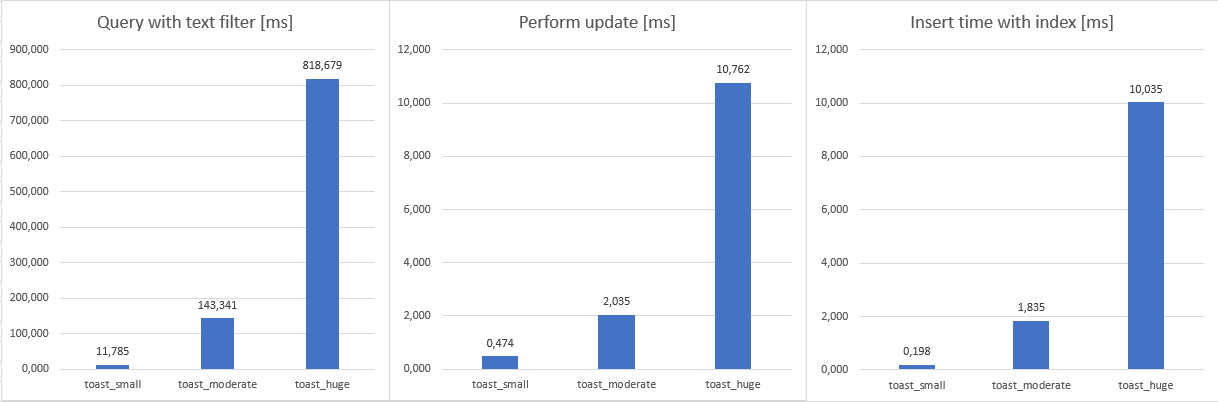
During some test, TOAST had some disadvantage due to data fragmentation. This test was the delete test (DELETE FROM xxxxx WHERE id = (SELECT id FROM xxxxx ORDER BY DESC LIMIT 1)). Due to fragmentation, it caused ~50% slowness against inline tables.
TOAST or not TOAST – Need another test
I was surprised when I saw the first and second test result that out of line policy was much faster then inline policy with longer records (but still within threshold). So, I decided to perform another test, where I can compare the performance, Previous test is not totally fair because record length was different.
My idea was to create 2 same table, but I will decrease the TOAST_TUPLE_TARGET value to 128 and I generate a simpler random string which only contains ‘0’ and ‘1’ characters. Then an insert will work on different way because, due to extended policy:
- Software compress the data if it is longer then 2kB
- If the compressed result size is smaller then
TOAST_TUPLE_TARGET, then it keep it in the line. Else, it put out of line. This value is 2kB in default.
I made 2 tables, same then above, only toast tuple target is different. Both table has 50000 records with 2100 character length. By this test, I was curious, that it is good to reduce this value on tables. I have performed the same test, then above, let’s see the results.
TOAST or not TOAST – Test and conclusion
Table size (includes table, index and TOAST size) was bigger where TOAST was used. Total size for no TOAST table was 27MB, same for TOAST table was 30MB. It is ~10% difference with same data.
For the first 2 tests, result same then before but performance difference was significantly smaller. Previous test, TOAST was 3 times faster than no TOAST. But in this case, it is only half time faster. When more ID was queried, difference was even smaller but still better at TOAST.
During next tests, result was same for both method. When there was query without content column, advantage above has disappeared. Due the data quantity was same, thus update and insert test has same result.
Disadvantages of fragmentation can be seen in delete and text filter test. Data quantity is same in both cases, but due to fragmentation, it takes more time.
Final conclusion
My final conclusion that, as the other aspects of the world, there is no universal rule because it depends from the application. I will go with text type in the future (rather than varchar), due to is more comfortable for and no performance penalty on text.
Regarding TOAST_TUPLE_TARGET value, it was a very interesting test. If data is inline, it has advantage when it needs to search in it, but if more record must be queried (not a single one), then the lowered toast tuple target can be good. Some example from my mind:
- For table which contains comments or updates, I would go with lower value, because usually more are queried in applications. It also usually not typical to filter among them
- For tables which contains blog post or pages, I would go with the default value (or even increase it), because usually only one is queried by index and TOAST does not matter there. And usually it has search in its body
Another interesting point to use indexes for those columns where we filter for medium sized no TOAST text is used. But, using too much indexes sometimes can have bad consequences. It considerable to separate these longer fields into a separated table but, of course, it also depends from the application.
Another important note that almost nothing is linear (or it is only in ideal environment). So the test above, I made that data quantity what I imagined to use in the future. In bigger/smaller numbers, results may different or another points are more important and other/extra tests are required.


