In this article, I will discuss what is in the database, what is the relationship among tables. Together with this, I will also discuss what information will be stored in the current version of this ticketing server.
This article is part of a series. Other already public articles:
Home Ticketing #1 – What my back(end) at home!
Home Ticketing #2 – High level overview
I have discussed the high-level overview of this solution in the previous article. Database is the bottom of everything, so this is the first thing, what I detail. I know, there are method where the code is the first which can handy in some situation, but I am old-fashioned guy, I prefer to figure out data, and their relationships, first. First, let us discuss what information to be stored in this database.
- Users: there can be more people who are using this instance and each of them can have different authority as role or reaching only limited servers and categories.
- Systems: as I mentioned, I plan to use it as a center of more of my devices. It would be handy to separate their tickets from managing view.
- Categories: every ticket could be in one stack, but for easier handling, I create categories (like: system, storage, network, etc.) where ticket can open separately.
- Tickets and their logs: the main reason cannot be miss why I do it. Of course, tickets and their logs must be stored, this is the point of this whole project. I store ticket headers and logs in different tables, because it would be not efficient to duplicate ticket header data in case of every single log.
You can see an overview figure about this whole architecture. I will detail it in the following paragraphs. Note: image is scanned from my handwritten notebook but I hope it is readable 🙂
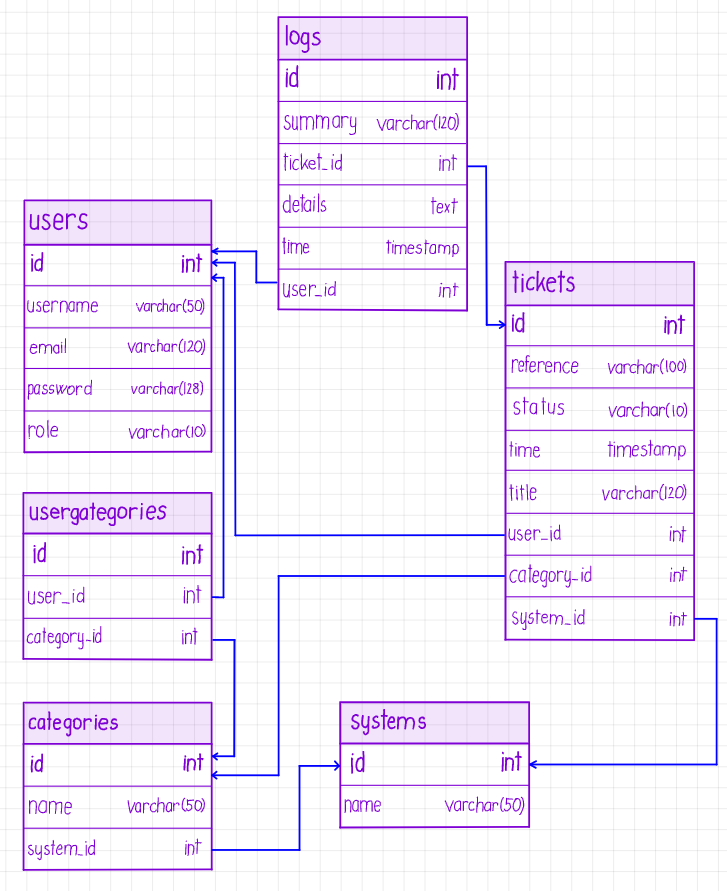
Systems and categories
First thing, what I discuss are the systems and categories tables as they are not depends from the rest of the table. Next to the primary key, the have no such many columns. Systems table only have a name where the system name can be stored. Categories also have one column and that is name too. Categories has a foreign key, called system_id. This is a connection between categories and systems.
Systems table has a constraint, which tells that name must be unique in the table. With other worlds, it is not possible to add more system with same system name. Categories table also have a constraint which tells that every name and system_id pairs must be unique. It is a protection if something bad would happen in the program logic.
In the following can be seen the CREATE TABLE statements for these tables:
CREATE TABLE systems
(
id integer NOT NULL SERIAL,
name varchar(50) NOT NULL,
CONSTRAINT systems_pkey PRIMARY KEY (id),
CONSTRAINT system_unique UNIQUE (name)
)
CREATE TABLE categories
(
id integer NOT NULL SERIAL,
name varchar(50) NOT NULL,
system_id integer,
CONSTRAINT categories_pkey PRIMARY KEY (id),
CONSTRAINT name_system_unique UNIQUE (name, system_id),
CONSTRAINT categories_system_id_fkey FOREIGN KEY (system_id)
REFERENCES public.systems (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL
)
Users
Minimal information is stored about every user.
- Username: every user needs a username. This username is displayed on the database (e.g.: who is the ticket owner or who made the log record, etc.)
- Password: password is stored in hash format. Every password is stored in SHA512 format. 512 bits is 64 bytes, but I store it as text and in hex format, so every character is 2 byte. Thus the size if password field is 128 bytese.
- Email: actually, it is not able to send any email notification, but I also plan to write some batch program which will be able to do. So this column is rather made for future than actual usage. This columns can be null because there can be users which are running batch on the system, so who just deliver the tickets as functional IDs.
- Role: normally everybody has User role. But there are some priviledged instruction what can be done only via Admin role. This is protected and verified by REST API.
There are 2 constraint in the users table, they tells that email and username must be unique (by separated not by pair). CREATE TABLE command of this table is the following:
CREATE TABLE users
(
id integer NOT NULL SERIAL,
username VARCHAR(50) NOT NULL,
password varchar(512) NOT NULL,
email varchar(120),
role varchar(10) NOT NULL,
CONSTRAINT users_pkey PRIMARY KEY (id),
CONSTRAINT email_unique UNIQUE (email),
CONSTRAINT username_unqie UNIQUE (username)
)
Users and categories
It can happen that not every user would like to (or can) see every ticket, system and categories. This is the reason why usercategories table has been born. It stores connection between users and categories. Users can make instructions (e.g.: assign, close) with those tickets where the user is connected (or their role is Admin). User_id and category_id pairs must be unique. It is also a protectiona against software errors to avoid incosistent table.
CREATE TABLE usercategories
(
id integer NOT NULL SERIAL,
user_id integer NOT NULL,
category_id integer NOT NULL,
CONSTRAINT usercategiryrelation_pkey PRIMARY KEY (id),
CONSTRAINT category_user_unique UNIQUE (user_id, category_id),
CONSTRAINT usercategiryrelation_category_id_fkey FOREIGN KEY (category_id)
REFERENCES public.categories (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT usercategiryrelation_user_id_fkey FOREIGN KEY (user_id)
REFERENCES public.users (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION
)
Tickets and logs
Tickets and logs are stored in different tables. Logs table contains log records (updates) about the current ticket. Every log record point to a ticket header, which contains ticket meta data. These ticket headers are stored in tickets table. There are connection between tickets and other tables (users, categories, system). First, I discuss the columns of tickets table.
- Category_id: it poins to the category where the ticket belongs
- Reference: every ticket has a reference value. Purpose of this value to avoid duplicate tickets about the same issue. For example there is a memory shortage in TEST-1 system. Its reference value can be anything, e.g.: “memory_shortage”. This issue is probably detected by a cron job or other batch. But it can run periodically. So, when next time this job run, it would create a new ticket with “memory_shortage” refrence value. Before the application create new ticket, it checks that “Is there any already opened ticket from this system with this reference value?”. If the answer is “yes”, then it will create a record update instead of a new ticket.
- Status: currently only 2 status is suspported: “Open” and “Closed”
- Time: it is a timestamp, when the ticket was created
- Title: title of the ticket, can indicate the topic or the nature of the ticket, e.g.: “Memory shortage”, “Extensive CPU usage”, etc.
- User_id: it points to the user who is the ticket owner
- System_id: it points to that system where the ticket came from
Logs table looks similar:
- Summary: similar role as “title” has in tickets table
- Ticket_id: points where the log belongs
- Details: can be longer text, even a command output. It can record more details about when the issue happened (e.g.: top command output)
- Time: when the record was made
- User_id: who made the record
CREATE TABLE tickets
(
id integer NOT NULL DEFAULT SERIAL,
category_id integer,
reference character varying(100) NOT NULL,
status character varying(10) NOT NULL,
"time" timestamp with time zone NOT NULL DEFAULT now(),
title character varying(120) NOT NULL,
user_id integer,
system_id integer NOT NULL,
CONSTRAINT tickets_pkey PRIMARY KEY (id),
CONSTRAINT tickets_category_id_fkey FOREIGN KEY (category_id)
REFERENCES public.categories (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT tickets_system_id_fkey FOREIGN KEY (system_id)
REFERENCES public.systems (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL,
CONSTRAINT tickets_user_id_fkey FOREIGN KEY (user_id)
REFERENCES public.users (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL
)
CREATE TABLE logs
(
id integer NOT NULL DEFAULT SERIAL,
summary character varying(120) NOT NULL,
ticket_id integer NOT NULL,
details text,
"time" timestamp without time zone DEFAULT now(),
user_id integer,
CONSTRAINT logs_pkey PRIMARY KEY (id),
CONSTRAINT logs_ticket_id_fkey FOREIGN KEY (ticket_id)
REFERENCES public.tickets (id) MATCH SIMPLE
ON UPDATE NO ACTION
ON DELETE NO ACTION,
CONSTRAINT logs_user_id_fkey FOREIGN KEY (user_id)
REFERENCES public.users (id) MATCH SIMPLE
ON UPDATE CASCADE
ON DELETE SET NULL
)
Final words
This is how the database is built up and relationships between tables. It is a result of a long process, I were thinking and redesing it longer period, because it is an important part of the project, as it is the core of everything. If this database structure is badly desinged, then it makes everything else more difficult. Note, that I am not an offical DBA expert, I just read forums, books and tried some thing on my home server, but I think, this structure will be OK for me on long term.

