
📝 Note
TLDR; I made a demo that is a simple chat service, written in Go. This service connects, using gRPC, to a Python service that calls OpenAI moderation API. Full source code of the demo is available here.Two services can be found in the demo:
- ChatService: A simple websocket based chat service, written in Go.
- ModerationService: A service that calls OpenAI API, written in Python.
Communication between services is done via gRPC. When a user send a message, before broadcasting it, it is validated using OpenAI moderation API. In this post, I don’t show all the code line-by-line, but I focus for the interesting part. Full source code can be found here.
🧨 Warning
During the post, I’m not just focus on code, but I also want to explain some design choices, trade-offs. In my opinion, it is very important to understand: there is no single “golden choice” that solves our problem. Everything has trade-off and when we decide the way, we have to analyze those trade-offs.
So, just because I use specific technologies in this post, it does not mean that other way are wrong. I explain my decisions during the post.
Microservice
Today, services become complex and sometimes managed by multiple teams. We have technologies like version control services, like GitHub, that makes the collaboration easier, but it has its limitation. Higher number of contributors requires more attention, more checks before any merge, that can slow down to deliver new functions.
Microservices try to solve this problem. Instead of having one very huge repository, we have more much smaller repositories, that can be managed by separated teams, independently from each other. But life is full of trade-offs: some problems are solved by microservices, but they also introduce new problems:
- Since services are separated from each other, they can be connected via network. This can increase the required network bandwidth.
- Not just the application logic separated, but also the data. In a monolith application we can use same database, so data is shared between all services. But with microservices, we have separated databases. So we need additional method to share data between services.
There are other trade-offs, but now I want to discuss these topics, because both belongs to the communication category.
Communication between services
There are several way for communication, but I want to show two of them: gRPC and Apache Kafka. Both of them are good, but for different approach, since they work in different ways
Using gRPC
The RPC refers to “Remote Procedure Call”. It has different implementations, gRPC is implementation of Google. The gRPC uses HTTP/2 as communication layer. So, if request is sent, we get response immediately. The basic developing flow with gRPC: we have a proto file, then we can generate code based on that file, then start to implement the services. Proto file for my demo can be seen below.
syntax = "proto3";
package moderation;
option go_package = "internal/grpc/moderation";
service ModerationService {
rpc CheckContent (ModerationRequest) returns (ModerationResponse);
}
message ModerationRequest {
string content = 1;
}
message ModerationResponse {
bool flagged = 1;
repeated string categories = 2;
}
With the proto file above, I generated Go and Python files for my services.
# For Go project
$ protoc --go_out=. -I ../proto --go-grpc_out=. moderation.proto
#
# For Python project
$ python -m grpc_tools.protoc -I ../proto/ --python_out=. --grpc_python_out=. moderation.proto
The gRPC uses protobuf to serialize and de-serialize data between services. This is something like JSON or XML, but faster and not text based. Documentation contains some useful example, for example for Go gRPC.
What are the major advantages of gRPC?
- Request is synchronous, good for tightly coupled services.
- Low latency between services.
- Simple authentication by using mTLS.
What are the major trade-offs of gRPC?
- Request is synchronous, that can be a disadvantage: if too much request is made it can have impact on the response time of service.
- Adding more consumer, requires code change.
- No built-in retry mechanism. So if gRPC call failed, we need to implement a retry logic.
Using Apache Kafka
Apache Kafka is a distributed event streaming platform. Producer can send events to Kafka topics, where consumers can read it. It tries to solve some trade-offs of gRPC.
- Adding more consumers can be done without code change of producer.
- If other service does not run, it can fetch the events from Kafka later using offset.
But it also has some trade-offs.
- Requests are asynchronous. So the producer cannot get direct response from consumer.
- Latency is bigger than with gRPC.
- Authentication is more complex.
- Requires more complex infrastructure.
gRPC vs Apache Kafka
As we read it, gRPC and Apache Kafka are not interchangeable. They are meant for different purposes
| gRPC | Apache Kafka | |
|---|---|---|
| Communication model | Request/Response (HTTP/2) | Pub/Sub (streaming) |
| Flow | Caller wait for processed response | Producer does not wait for consumer |
| Persistency | No built-in Persistency | Messages are durable |
| Retry logic | Manually implemented | Built-in retry, replay via offset |
| Adding more consumer | Difficult, need code change | Simple, no code change need |
| Operational complexity | Lightweight | Complex |
| Observability | Easy trace with tools like OpenTelemetry | Needs complex monitoring |
They can be used in a hybrid approach as well. For example, we have a web shop service that we provide. When we create a new order, it can be done via gRPC when it is registered to a database and got an ID. But other events, like adding a new item into a car or submit an order, can be done via Apache Kafka. So all other service can see the ID of the order, and react for different events, such as a notification or analytics service
Why gRPC and not REST?
This is a very good question. At first look, they seems very similar, both can be done on HTTP/2 application layer, both serialize and deserialize data. But there is a very significant difference between them.
Using REST, nothing gives us hint, what parameters we want to pass on. We can read documentation of course (e.g.: OpenAPI specification), but the editor or testing tool, does not give a warning or error if we pass, e.g.: a number instead of a string.
With gRPC we call functions in our code that has parameters which has types (if language has types). In this case, if we pass a number instead of a string, IDE, tester, builder, everything gives an error.
From performance-wise, protobuf is more efficient than JSON and it can deliver binary data too, not just text. The gRPC is able to stream the data, e.g.: streaming log, instead of polling with REST API. A lot of REST API still uses HTTP/1.1 which decrease the performance.
Moderation API of OpenAI
OpenAI provides a moderation API. It can be used to moderate text and images as well, and this is free within a fair usage.
📣 Important
Every information about this API is true on the day, when the post was written. For up-to-date information, always looking for official documentation of OpenAI.Usage
This API can be easily used via official SDKs or via a simple curl. Documentation of this API is here.
💡 Tip
If you type a command on terminal, it is added to your history. But with an easy trick, it can be bypassed for sensitive information:
# This is logged as history
$ export OPENAI_API_KEY=my_key
# This is not logged due to command starts with a space
$ export OPENAI_API_KEY=my_key
$ curl -s https://api.openai.com/v1/moderations \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "omni-moderation-latest",
"input": [{"type": "text", "text": "I wish, I could kill myself"}]
}'
Sample response for the request:
{
"id": "modr-800",
"model": "omni-moderation-latest",
"results": [
{
"flagged": true,
"categories": {
"harassment": false,
"harassment/threatening": false,
"sexual": false,
"hate": false,
"hate/threatening": false,
"illicit": false,
"illicit/violent": false,
"self-harm/intent": true,
"self-harm/instructions": false,
"self-harm": true,
"sexual/minors": false,
"violence": true,
"violence/graphic": false
},
"category_scores": {
"harassment": 0.0007314205575305067,
"harassment/threatening": 0.000873249922286427,
"sexual": 0.000057031570707833595,
"hate": 0.000016346470245419304,
"hate/threatening": 0.000008220189478350845,
"illicit": 0.005296586604653562,
"illicit/violent": 0.00003625900662832244,
"self-harm/intent": 0.9987178785733406,
"self-harm/instructions": 0.0003465039855257002,
"self-harm": 0.9753485669350461,
"sexual/minors": 0.000004006369222920725,
"violence": 0.43006728982700637,
"violence/graphic": 0.0015731933694596465
},
"category_applied_input_types": {
"harassment": ["text"],
"harassment/threatening": ["text"],
"sexual": ["text"],
"hate": ["text"],
"hate/threatening": ["text"],
"illicit": ["text"],
"illicit/violent": ["text"],
"self-harm/intent": ["text"],
"self-harm/instructions": ["text"],
"self-harm": ["text"],
"sexual/minors": ["text"],
"violence": ["text"],
"violence/graphic": ["text"]
}
}
]
}
Moderation are done based on different categories. This API cannot be configured to tolerate things, that are natural on our website. For example, if website contains sexual content, moderation still done. Although, we can simply ignore the sexual related categories on our backend.
Limits
Like everything that is free, has a limit for fair usage. In case of this API, the limit, for free tier, is 10,000 token per minute. But what does it mean?
- “Brooo that final boss in Elden Ring?? Took me 4 hours and 0 dignity left 😭😭”. This message is 24 token.
- First Harry Potter book is roughly 100,000 token.
- Average business email is ~200 token long, that means check ~50 email per minute.
In my opinion, this rate limit is more generous.
Where is the catch?
Rate limit seems generous. It does not incur any usage cost on OpenAI’s side. This is too good to be true, right?
If we talk about a personal project, early startup of if we make just an MVP, then this is fine, even free tier, no objections. But think about it later, if startup starts to grow:
- You may need more customized moderation service
- Your traffic may increase
Then free tier won’t be enough anymore. To have a custom moderation model, you need to train one for yourself. You need more moderation request, it costs more. At some point, as you grow, you may reach this point. And if you have used OpenAI before, it will be difficult to replace it, mainly if you have embedded it into your services. This is called vendor lock-in. You have to go pay money on it as you grow. But these are things that you must calculated when you have a company, what happens as you grow.
If you use this in a separate service, then it can be easier to replace for a different model or service provider functions. If your website has, e.g.: sexual content, you can just simply ignore sexual related categories. So there are tricks that can growing more comfortable.
Implementation
After some word, let’s see how this is implemented. I don’t describe the whole code line-by-line, I focus on websocket, gRPC and Python service part. The website host and the login API is such simple, I don’t even mention it. This chat application is very simple, no rooms, no private chats: just a simple room where each moderated message is broadcast message.
📣 Important
Do not use this code on “as-is” in production code. This is a very unsecure demo.The gRPC related files can be generated by using gRPC related tools.
# For Go project
# Install go utilities:
# go install google.golang.org/protobuf/cmd/protoc-gen-go@latest
# go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest
$ protoc --go_out=. -I ../proto --go-grpc_out=. moderation.proto
#
# For Python project
# Need to install: pip install grpcio grpcio-tools
$ python -m grpc_tools.protoc -I ../proto/ --python_out=. --grpc_python_out=. moderation.proto
Implementation of chat service
I defined the message and ChatHub structures.
type message struct {
Sender string `json:"sender"`
Content string `json:"content"`
}
type chatHub struct {
upgrader websocket.Upgrader
clients map[string]*websocket.Conn
broadcast chan message
mutex sync.Mutex
moderationClient moderation.ModerationServiceClient
}
func newChatHub() chatHub {
conn, err := grpc.NewClient(
"localhost:10200",
grpc.WithTransportCredentials(insecure.NewCredentials()),
)
if err != nil {
slog.Error("failed to initialize client", "error", err)
panic(err)
}
return chatHub{
clients: map[string]*websocket.Conn{},
broadcast: make(chan message),
moderationClient: moderation.NewModerationServiceClient(conn),
}
}
The base idea is, if new user connects, I add it for clients map. If any user
send a message, the message is sent to broadcast channel after moderation.
There is a go routine which is checking if anything comes in the broadcast channel.
func (h *chatHub) startBroadcast() {
slog.Info("start broadcast hub")
for msg := range h.broadcast {
slog.Info("broadcast message", "message", msg)
h.mutex.Lock()
for username, userConn := range h.clients {
slog.Info("send message", "username", username)
err := userConn.WriteJSON(msg)
if err != nil {
slog.Error(
"failed to send message client",
"error", err,
)
delete(h.clients, username)
}
}
h.mutex.Unlock()
}
}
The /ws endpoint handler is the serveWs function.
func (h *chatHub) serveWs(w http.ResponseWriter, r *http.Request) {
// Upgrade HTTP connection to websocket
conn, err := h.upgrader.Upgrade(w, r, nil)
if err != nil {
slog.Error(
"failed to upgrade connection",
"error", err,
)
return
}
// Add user to the clients map
username := r.URL.Query().Get("user")
h.mutex.Lock()
h.clients[username] = conn
h.mutex.Unlock()
// Wait for incoming messages from user
for {
// After receiving parse it as `message` JSON structure
var msg message
err := conn.ReadJSON(&msg)
if err != nil {
slog.Error(
"failed to read input json",
"reason", err,
)
h.mutex.Lock()
delete(h.clients, username)
h.mutex.Unlock()
break
}
slog.Info("received message", "message", msg)
// Perform the CheckContent gRPC call
// This sends the message content to the moderation service and wait
// for its response.
ctx := context.Background()
res, err := h.moderationClient.CheckContent(ctx, &moderation.ModerationRequest{
Content: msg.Content,
})
if err != nil {
slog.Error("failed to connect for moderation", "error", err)
continue
}
// If flagged for any reason, then deny to send it to other users
if res.Flagged {
slog.Warn("blocked messaged", "flags", res.Categories)
warning := message{
Sender: "MODERATION",
Content: fmt.Sprintf(
"⚠️ Your message was blocked due to policy violation: %+v", res.Categories,
),
}
conn.WriteJSON(warning)
continue
}
// At this point moderation is done and everything fine, send message
// to broadcast
h.broadcast <- msg
}
}
Implementation of moderation service
Implementation of this service is a single file. With some comment, it can be seen below.
import os
import grpc
from concurrent import futures
from openai import OpenAI
import moderation_pb2
import moderation_pb2_grpc
class ModerationService(moderation_pb2_grpc.ModerationServiceServicer):
def CheckContent(self, request, context):
try:
# Here I use OpenAI module
# pip install openai
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
response = client.moderations.create(
model="omni-moderation-latest",
input=[{"type": "text", "text": request.content}],
)
result = response.results[0]
flagged = result.flagged
categories = [k for k, v in result.categories if v]
print(flagged, categories)
# Very simple service, just send back the original response
# of moderation API. No extra check or classification in the demo.
return moderation_pb2.ModerationResponse(
flagged=flagged, categories=categories
)
except Exception as e:
context.set_details(str(e))
context.set_code(grpc.StatusCode.INTERNAL)
return moderation_pb2.ModerationResponse()
if __name__ == "__main__":
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
moderation_pb2_grpc.add_ModerationServiceServicer_to_server(
ModerationService(), server
)
server.add_insecure_port("[::]:10200")
server.start()
print("listen on :10200")
server.wait_for_termination()
See while it’s working
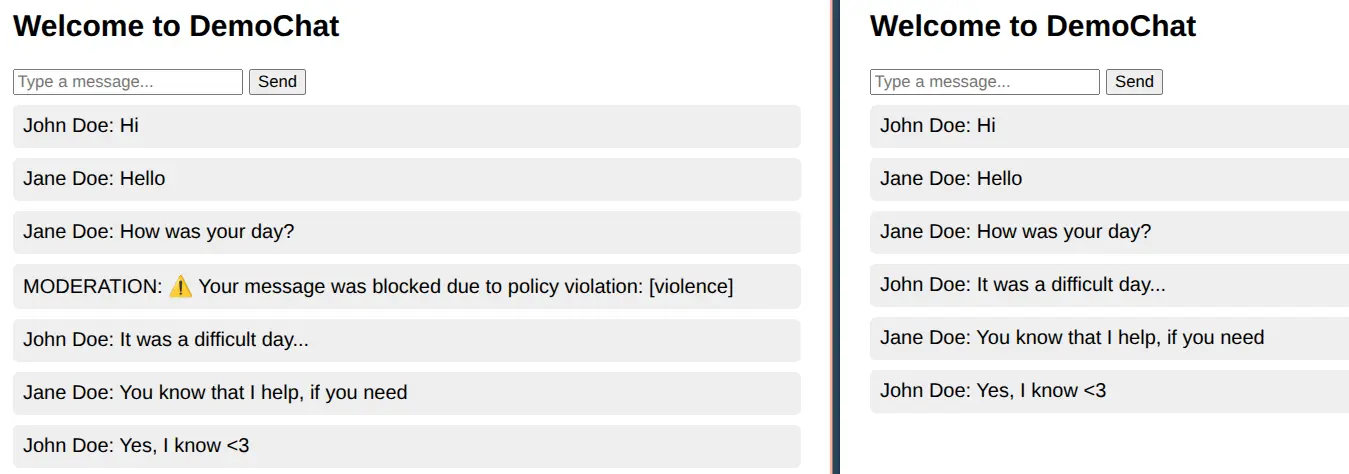
Final words
I have never integrated AI related services among my services, but this small demo and train of thoughts, give me some view how it could be done. It is just a demo service, of course, on a real production ready implementation some settings are different, because of different trade-offs.
I enjoyed to work on it, and it motivates me to dig deeper in this topic. Not necessarily with OpenAI – it could be a different model of course, but with the topic itself.